
Security Intelligence Briefing: NVD Updates & AI-Driven Threats Topic: NIST NVD Operations, CVE Management, and AI Discovery The cybersecurity landscape is currently undergoing a structural shift, defined by two converging forces: a massive influx of reported vulnerabilities managed by the NVD, and the rapid acceleration of AI-driven discovery. In April 2026, the National Institute of … Continue reading Security Intelligence Briefing: NVD Updates & AI-Driven Threats
Troubleshooting System Prompts in AI-Powered SIEM Solutions
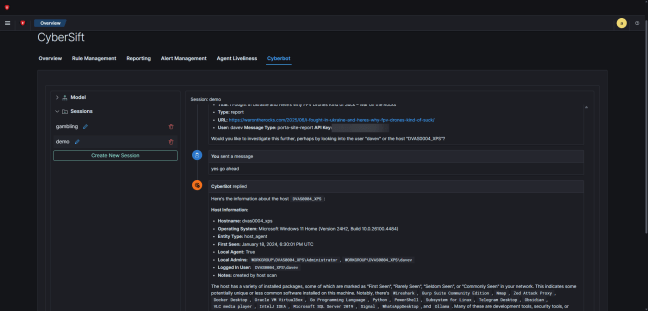
The last three months have been frantic at Cybersift development - mainly due to the inclusion of generative AI into the SIEM. The backend currently powering the LLM chat interface on our SIEM is based off the excellent PydanticAI library. I like the approach taken by this library - while it helps reduce the boilerplate … Continue reading Troubleshooting System Prompts in AI-Powered SIEM Solutions

You must be logged in to post a comment.