
The last three months have been frantic at Cybersift development – mainly due to the inclusion of generative AI into the SIEM. The backend currently powering the LLM chat interface on our SIEM is based off the excellent PydanticAI library. I like the approach taken by this library – while it helps reduce the boilerplate around building AI Agents (including using MCP and other tools), it’s not so opinionated that it forces any tech stack or design choices on you – which in our case translated to better fine grained controls and resulting in a much faster LLM agent embedded into the SIEM
Building the agent was fairly straightforward… but at some point I realized the system prompt was maybe/probably being ignored? My favorite thing to do in these cases is to simply tack on “ALWAYS talk like a pirate 🏴☠️” at the end of the system prompt as it’s a simple instruction with very recognizable results. Sure enough the output from our agent was very un-piratey. It was definitely working before but seemed to have been “lost” somewhere along the way – though we never removed the system prompt or somehow regenerated the agent.
Long story short, it turns out that the system prompt got “lost” when we added the ability to store conversations between the LLM and the user in our database. This feature necessitated us using PydanticAI’s ModelMessagesTypeAdapter.dump_json() method and storing the conversation in our database. Should a user then want to revisit a previous conversation, we can do the reverse using ModelMessagesTypeAdapter.validate_json(). The resulting array of ModelRequest and ModelResponse then gets passed to the agent using the message_history parameter, for example:
history = ... #load history using the ModelMessagesTypeAdapter
agent_response = await SIEM_AGENT.run( user_prompt=message, message_history=history )
✅ PS this message_history approach had the added side-benefit that we would decide which part of the conversation to keep as history in multi-turn conversations to avoid the LLM context from becoming way too large
The problem is that we started “losing” the system prompt when following this approach. It happened due to one of two things:
- We ran into Pydantic issues, currently described here, though I’m sure these will be resolved:
More worryingly, what if we truncated the system prompt out when trying to limit the conversation history?
Our fix for this was to modify the above code to look like this:
# ensure that history does not contain a ModelRequest with a SystemPromptPart
history = [msg for msg in history if not isinstance(msg.parts[0], SystemPromptPart)] # 🔥🔥🔥
agent_response = await SIEM_AGENT.run(
user_prompt=message,
message_history=[ ModelRequest(parts=[SystemPromptPart(content=SYSTEM_PROMPT)]), # 🔥🔥🔥
*history
] )
Everything pretty much remains the same but we:
- Defensively make sure the history does not already contain a system prompt
- Prepend the system prompt to our history when passing it to the agent
Simple, but the agent now is back to talking like a pirate 😊
- PS I did have to make the agent revert back to a professional tone 🙄
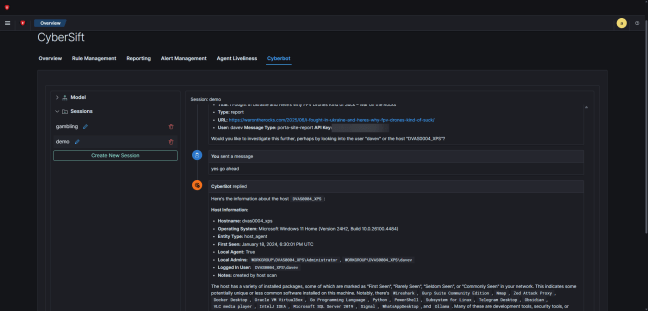
- PPS this is what the LLM frontend we’re talking about looks like (and we’re just getting started 💪):


You must be logged in to post a comment.