
In this article we’ll explore how Principal Component Analysis [PCA] [1] – a popular data reduction technique – can help a busy security or network administrator. Any such administrator has often been faced with a daunting problem… going through reams of firewall or router connection logs trying to figure out if any of the thousands of entries is abnormal or not, if it’s worth looking into, or even where to start. We’ll use an open source data analysis tool called RapidMiner [2] to explore how to tackle this exact problem and give admins a head start.
PCA may sound complicated – but breaking it down to its bare essence reveals a not so complicated concept. Given a CSV or table, PCA applies statistical and mathematical techniques to figure out which of the columns in the data actually have the most “impact” or variance in statistical speak. To illustrate this point… imagine having a the following really simple table:
| Destination IP Address | Protocol |
+———————————+————-+
| 192.168.1.1 | tcp |
| 192.168.10.7 | tcp |
| 192.168.4.3 | tcp |
It’s pretty intuitive that the only column adding any real value or having any real impact is the destination IP address, because it’s the only column whose value changes. The protocol column only contains “tcp” (it has no variance) and so doesnt really add much to figuring out if a connection is anomalous. PCA automates this process over a potentially large number of columns, and tells the analyst which columns have the most impact. I recommend you read the article [3] to get a good background into exactly how we’ll be extracting this information using RapidMiner.
Preparing the firewall logs
In this case, we’ll be using PaloAlto “Traffic” logs, exported to a CSV file. This results in a rather large data set, so either beef up your machine, or reduce the data set. For the purposes of the article, we’ll have to reduce the data set. So we keep only the first 10,000 rows, and reduce the number of columns by making some educated guesses as to which columns can be removed. For example, constant columns like “Serial Number”, “Domain”, “Config Version”, and so on can be eliminated. Other columns that do not add too much value such as “receive time” are also eliminated. It takes some practice but you should be able to very quickly determine which columns actually do make a difference. In this case, we retained the following columns:
Source address
Destination address
Application
Source Port
Destination Port
IP Protocol
Action
Bytes
Bytes Sent
Bytes Received
Packets
Destination Country
pkts_sent
pkts_received
PCA normally only takes numeric input, and some of these columns contain alphanumeric data. So we now need to convert all data to numbers only. A really simple way of doing this is just to convert each cell to it’s ASCII equivalent. So “abc” would be 97+98+99=294
I wrote a really simple python script that iterates through the CSV file and converts everything to the decimal ASCII equivalent. The script takes as an input a file called “log_prepared_truncated.csv” and outputs to a file called “log_transformed_truncated.csv”, and it assumes the first row contains column names so it leaves them untouched.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| import csv | |
| with open('log_transformed_truncated.csv', 'w') as outfile: | |
| c = csv.writer(outfile) | |
| counter = 0 | |
| with open('log_prepared_truncated.csv','rb') as f: | |
| for row in csv.reader(f, delimiter=','): | |
| counter = counter + 1 | |
| mod_row = [] | |
| if counter != 1: | |
| for cell in row: | |
| mod_row.append(sum(bytearray(cell))) | |
| else: | |
| for cell in row: | |
| mod_row.append(cell) | |
| c.writerow(mod_row) | |
| print "processed {} rows".format(counter) |
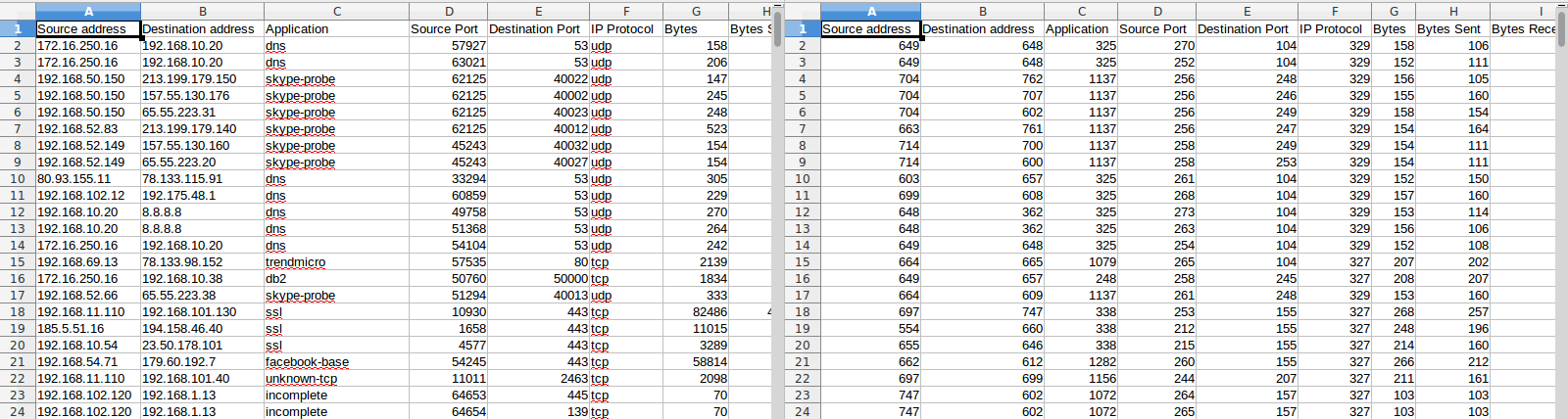
Here we can see the original CSV file on the left, and the transformed CSV file on the right:
Introducing RapidMiner
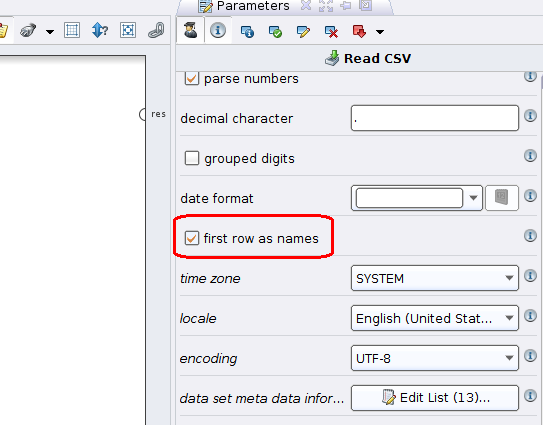
RapidMiner has a very simple UI…. it should be very intuitive to use. We first import our transformed CSV file. Just type “csv” into the search bar on the left hand side and click-drag the “Read CSV” operator. Clicking on the Read CSV operator gives you the option to run “Import Configuration Wizard” which makes it all dead simple. You can leave all parameters as default, except for ticking “first row as names”:
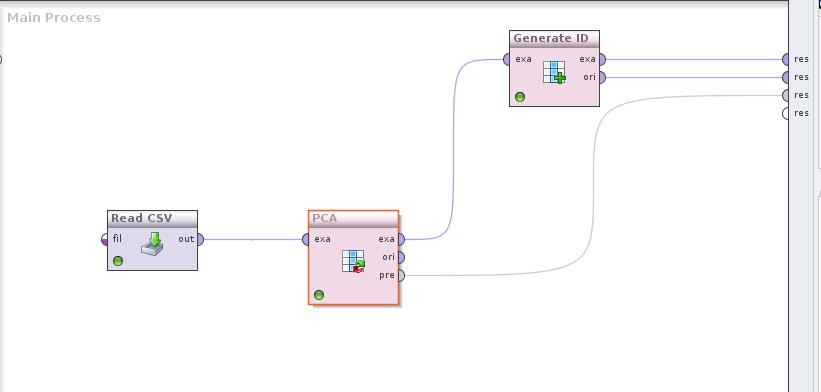
Next, we add the PCA operator. Simply type “pca” into the search box and click-drag the “Principal Component Analysis” operator, and connect the two operators together. I also like to include a “generate ID” operator which will number the outputted rows and make it easier to refer back to the original data. So the final process should look like this:
Focus on PCA
Before moving to the final results, let’s stop and look a bit at the PCA stage. Hit the run button… In the results, have a look at the “PCA (PCA)” tab:
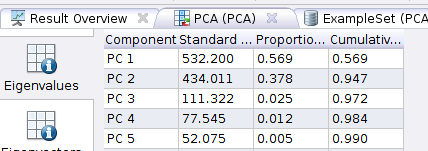
In the above, we note that the first two component – PC1 and PC2 – together account for 94.7% of the variance in the data (that’s the last column in the above screenshot). So these two components are what we’ll focus on. Which columns do these component map to? That’s where “Eigenectors” come in. Click on the Eigenvectors button: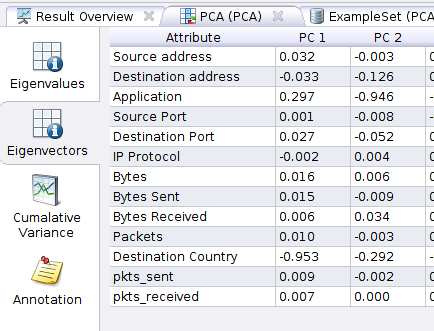
PC1 is most influenced by “Destination Country” because that Attribute contributes -0.953 to the component (the maximum can be +/- 1), while PC2 is influenced most by “Application”. So now we know that these two attributes are what impact our data most.
Visualizing the results
A picture is worth a thousand words. So let’s generate some 🙂
Click on the “ExampleSet (Generate ID)” tab, and then hit the “Charts” button. To get a good idea of which is the best plot to choose, my favorite first port of call is the “Scatter Matrix”, which gives all possible permutations of scatter plots… in our case it’s quite simple… either (PC1 vs PC2) or (PC2 vs PC1). Make sure to select “id” as plots, and we should see something like the below:
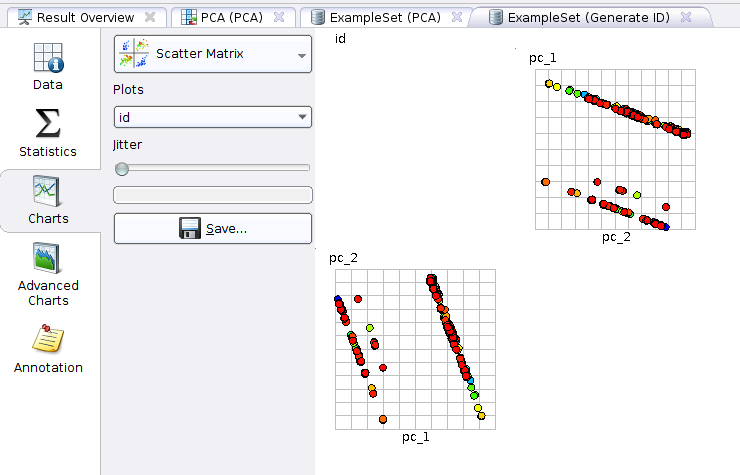
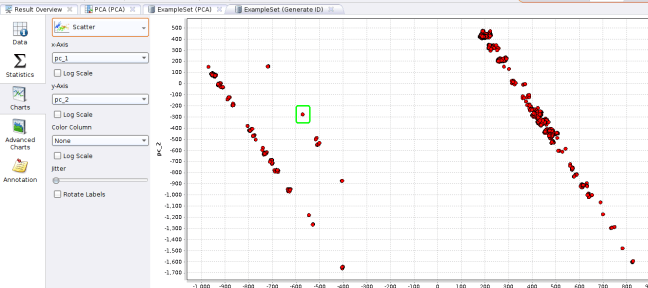
The above is much more helpful when you have more than two components being plotted. Switching to a simple scatter plot, we already see useful data emerging:
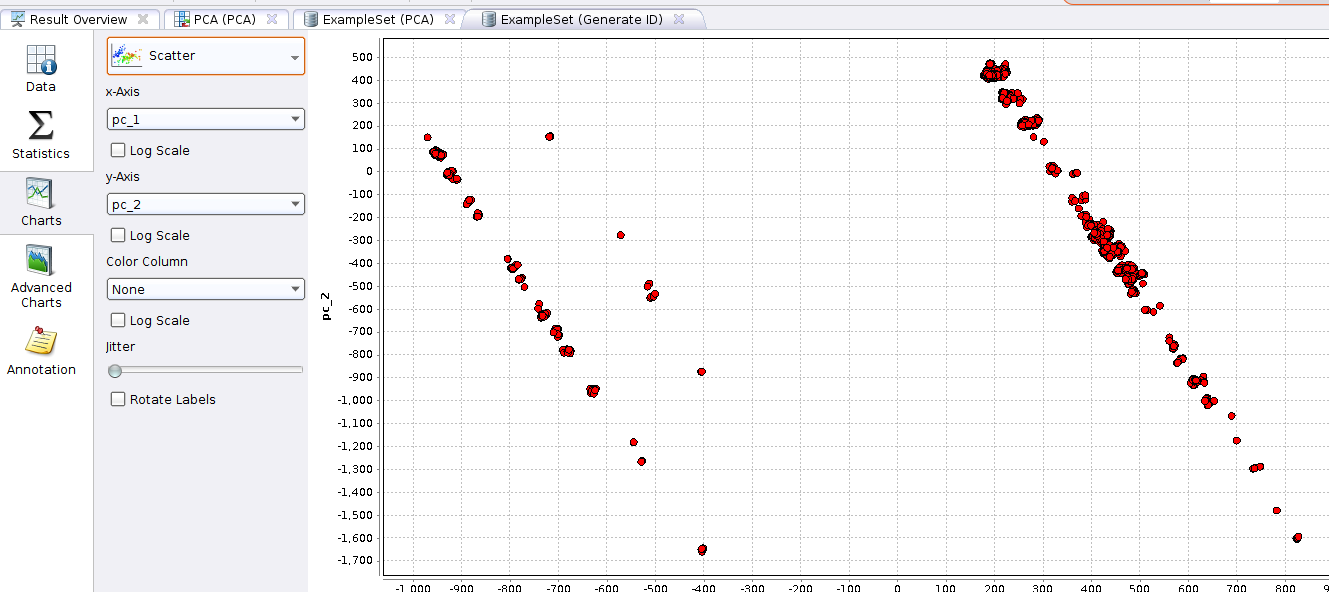
Most points are grouped together… but there are a few that dont quite fit in… these are our “outliers” that we should have a closer look into… Hover your mouse over a point of interest and note the ID.
As a quick example, one point from the above screenshot immediately stands out, circled in green below:
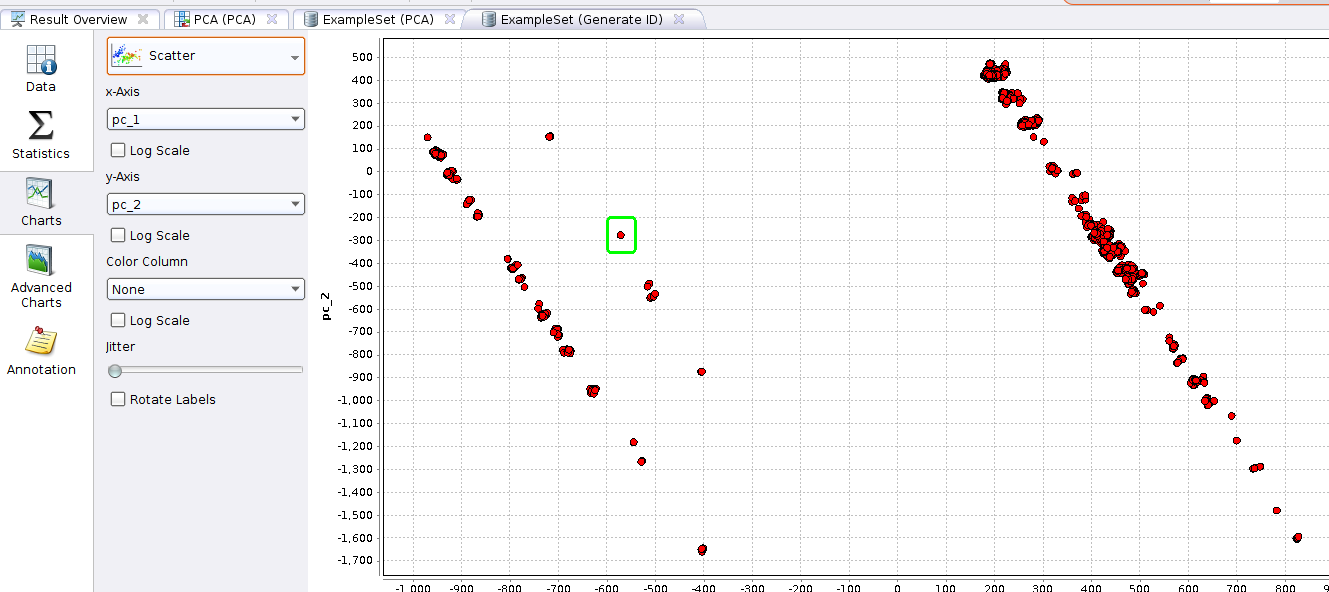
The ID for this point is 6671. So we go back to our original CSV file (log_prepared_truncated.csv) and see what comes up on row 6671. In this case its:
216.218.206.82 194.158.46.42 incomplete 44181 80 tcp 120 60 60 3 MT 2 1
Something is already weird here… the destination port is “80” but application is not “incomplete” rather than “HTTP” as I’d have expected it. So we put “216.218.206.82” into my next favorite tool… IBM’s X-Force Exchange [4], and indeed… this is an IP that’s associated with scanning…
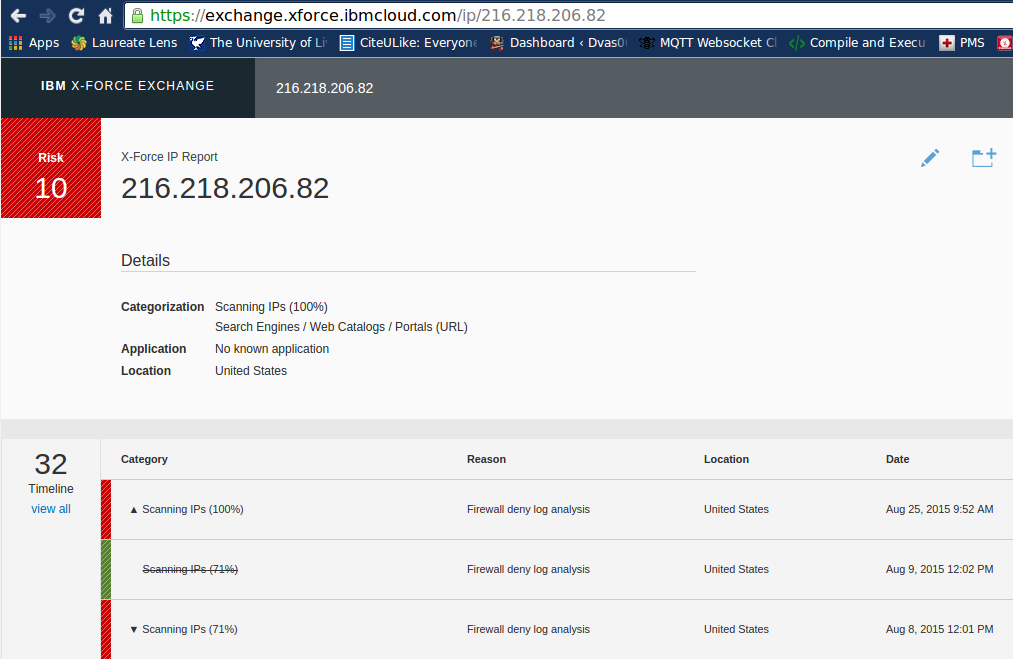
Rinse and repeat…. 🙂
References
[1] Principal Component Analysis – Wikipedia. Available from: https://en.wikipedia.org/wiki/Principal_component_analysis
[2] RapidMiner. Available from: https://rapidminer.com/
[3] How to run Principal Component Analysis with RapidMiner – Part 2. Available from: http://www.simafore.com/blog/bid/62911/How-to-run-Principal-Component-Analysis-with-RapidMiner-Part-2
[4] IBM X-Force Exchange. Available from: https://exchange.xforce.ibmcloud.com

One thought on “Data mining firewall logs : Principal Component Analysis”
Comments are closed.