

Maybe the link between your smartphone keyboard and current machine learning research in cybersecurity is not apparent at first glance, but the technology behind both is extremely similar: both leverage deep learning architectures called Recurrent Neural Networks [RNNs], specifically a type of RNN called Long Short Term Memory [LSTM].
One of the main advantages of LSTMs is their ability to deal with sequences very well. Due to the composition of the building blocks of LSTMs, these RNNs are able to predict the next step in a sequence given previous steps by taking into account not only the statistical properties of a sequence in question (e.g. frequency) but also the temporal properties of a sequence. To give a practical example of “temporal properties”, let’s imagine a simplistic example. Say an LSTM has been trained with sequences similar to the following:
previous steps -> next step
“1 1 1” -> 2
“4 4 4” -> 5
Given the never-before-seen sequence of “8 8 8” the LSTM is very well able to predict “9” correctly. This may seem simplistic but a neural network typically deals with thousands or millions of different sequences, but the LSTM is anyway capable of learning the intuitive rule in our example that if you see three repeated numbers, the next number is simply +1. This is different from spatial or frequency based machine learning techniques (such as One Class SVMs) where a never-before-seen sequence gets classified as an anomaly — precisely because it’s never been seen before.
Your smartphone keyboard is actually powered by deep learning
You probably use LSTMs every day without realizing it — in the form of the predictive text suggestions that appear whenever you are typing something in your smartphone. As we just explained, LSTMs are very good with sequences. Sequences can just as well be letters rather than numbers. So given enough training, given a previous sequence of letters, an LSTM gets very good at suggesting the next letter, couple of letters, or the whole word.
The screenshot above is familiar to all of you… start typing and given a sequence of characters, the LSTM will predict the most probable next few characters. These “predictions” are what we call suggestions.
Where things get interesting for cybersecurity analysts is what happens when we feed an LSTM a sequence of characters which are abnormal.
An example of doing this on your smartphone is shown above. When we feed the LSTM an abnormal sequence of characters, it cannot predict with any certainty what the next character is. This manifests itself in very limited suggestions. In the screenshot, note how the keyboard suggestions are limited to the sequence itself (LSTM could not predict the next character, or it simply prepends common characters).
The cybersecurity tie-in
One man’s trash is another man’s gold. While the above might not seem very useful to the smartphone user — it is to a cybersecurity analyst who is looking for anomalies within the millions of logs that are generated by security devices.
For example, let’s consider CyberSift’s Docker anomaly detection engine. The concept is pretty simple: detect anomalous sequences of system calls. Any operating system’s activity can be characterized as a stream of system calls like so:
open-read-read-write-poll-listen-accept-close
We can imagine each system call as being a character or number in a longer sequence — exactly what LSTM is designed to handle. To give a practical example, let’s imagine we are using an LSTM that has been trained on common sequences of system calls. Next, we see how the LSTM reacts when we ask it to predict the next system call, given a sequence of syscalls which is relatively common. The LSTM output could look similar to this:
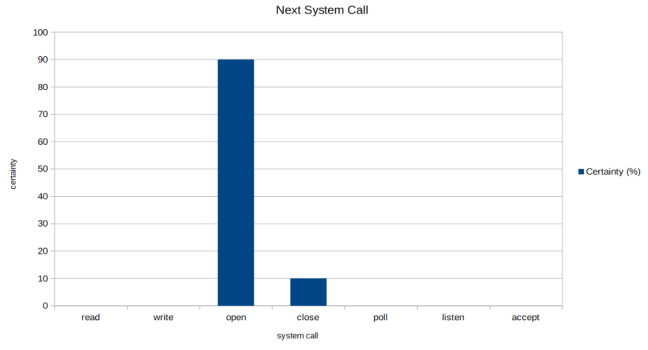
The above graph shows that the LSTM is 90% certain that the next syscall is going to be “open”. Similar to what we saw before with the smartphone keyboard, the LSTM network has a good chance of being correct.
Contrast this to what happens when we feed the LSTM network an unusual syscall sequence. Just like before, the LSTM network will get confused and give very uncertain predictions:
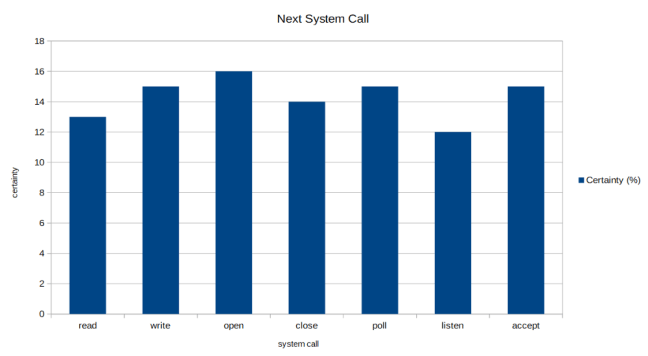
The above graph still shows “open” as being the next most probable system call, but the network is a lot less certain about it (16% vs the 90% we had previously)
This is exactly how CyberSift leverages deep learning to help detect anomalies in your docker environment — or to detect anomalies within your logs, highlighting those sequences that are different or unusual and therefore are more worthy of your limited time.
These types of protections are becoming increasingly important as novel attacks are discovered against docker and other systems which do not necessarily trigger signatures, but definitely generate anomalous behavior.

Consider the attack presented in Black Hat just last month — where hackers were able to spin up a docker container just by having a target visiting a specially crafted webpage. Their attack consists of leveraging the docker API to start a container and then use that to laterally attack the network. In a busy docker environment, where containers are being started and stopped multiple times within a short period of time, keeping your eye on all the containers being started may be a bit too much to handle, but as we can see from CyberSift’s anomaly detection engine output below — starting a container that performs unusual actions shows up as a highly anomalous period:

For more posts like this, written in my capacity as CTO of CyberSift, please follow us on Medium! We include more technical, marketing, and management articles all relating to InfoSec
