

In our previous post, we explored how we detect anomalies in time series using the 3 sigma rule using Influx. In this article we’ll do the same using Grafana
As a quick recap, the 3-sigma rule states that approximately all our “normal” data should be within 3 standard deviations of the average value of your data. This article explorers how we can measure standard deviations from the mean and alert whenever this goes above 3.0 (in order words, our Z-Score goes above 3.0) using Grafana + Prometheus

So we need to query Grafana for three things:
- A datapoint to describe a range interval (x)
- The mean of our data over a longer period of time (μ)
- The standard deviation over the same (longer) period of time (σ)
For the sake of discussion, let’s focus on the “node_disk_writes_completed_total” metric. The mean and standard deviation are very easily extracted using the in-built functions in Prometheus:
avg_over_time(node_disk_writes_completed_total{instance="$node",job="$job",device=~"$diskdevices"}[1d]))stddev_over_time(node_disk_writes_completed_total{instance="$node",job="$job",device=~"$diskdevices"}[1d])The above two expressions would give us the average and standard deviation calculated over a day – hence the [1d] range variable.
The last piece of the puzzle is to grab a datapoint… “x” in our formula above. I tackled this by just taking another average over time, but of a range interval equal to the dashboard variable rather than fixed to 1 day as above:
avg_over_time(node_disk_writes_completed_total{instance="$node",job="$job",device=~"$diskdevices"}[$__rate_interval]Note the use of [$__rate_interval] above: https://grafana.com/docs/grafana/latest/datasources/prometheus/#using-__rate_interval
Putting it all together
So implementing our formula above, we get the following query:
(avg_over_time(node_disk_writes_completed_total{instance="$node",job="$job",device=~"$diskdevices"}[$__rate_interval])-avg_over_time(node_disk_writes_completed_total{instance="$node",job="$job",device=~"$diskdevices"}[1d]))/stddev_over_time(node_disk_writes_completed_total{instance="$node",job="$job",device=~"$diskdevices"}[1d])Results
The above queries where written against an input source whose graph was as follows:
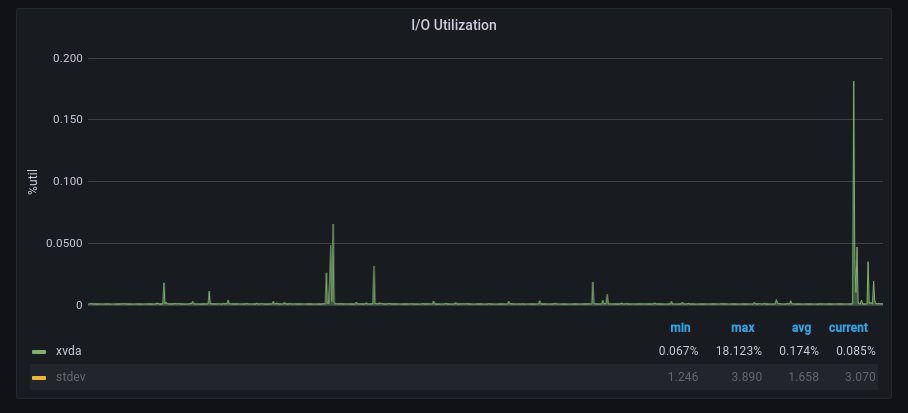
Note the large spike to the right, we would want to be alerted to such a large spike, but not necessarily the smaller spikes to the left. This is what our anomaly check gives us:
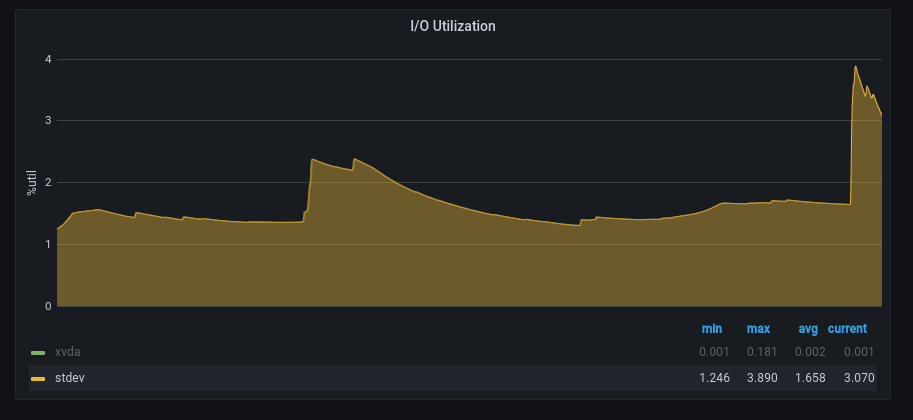
If a threshold of >= 3 is set, then the smaller spikes would not give an alert, but our large spike would since it is quite a large spike.
Another example would be the below time series:
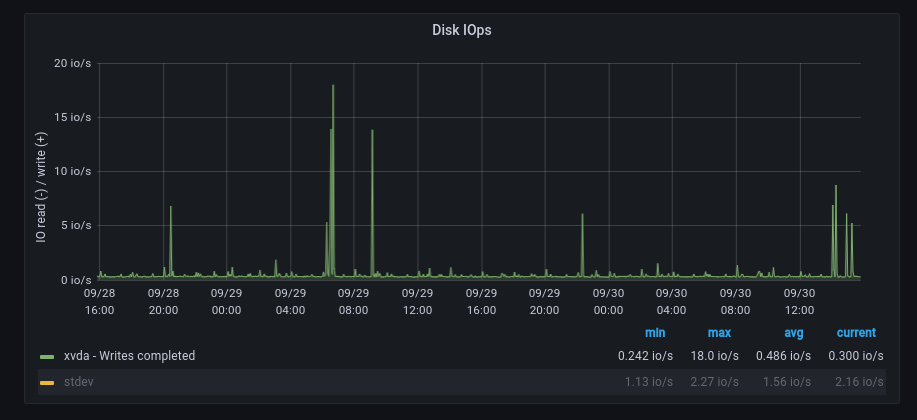
The above time series has many more spikes (in signal-speak the time series is a lot more “noisy”), so we wouldn’t want a static threshold that fires on every spike, but only on spikes which are out of the norm. Running our anomaly query we get:

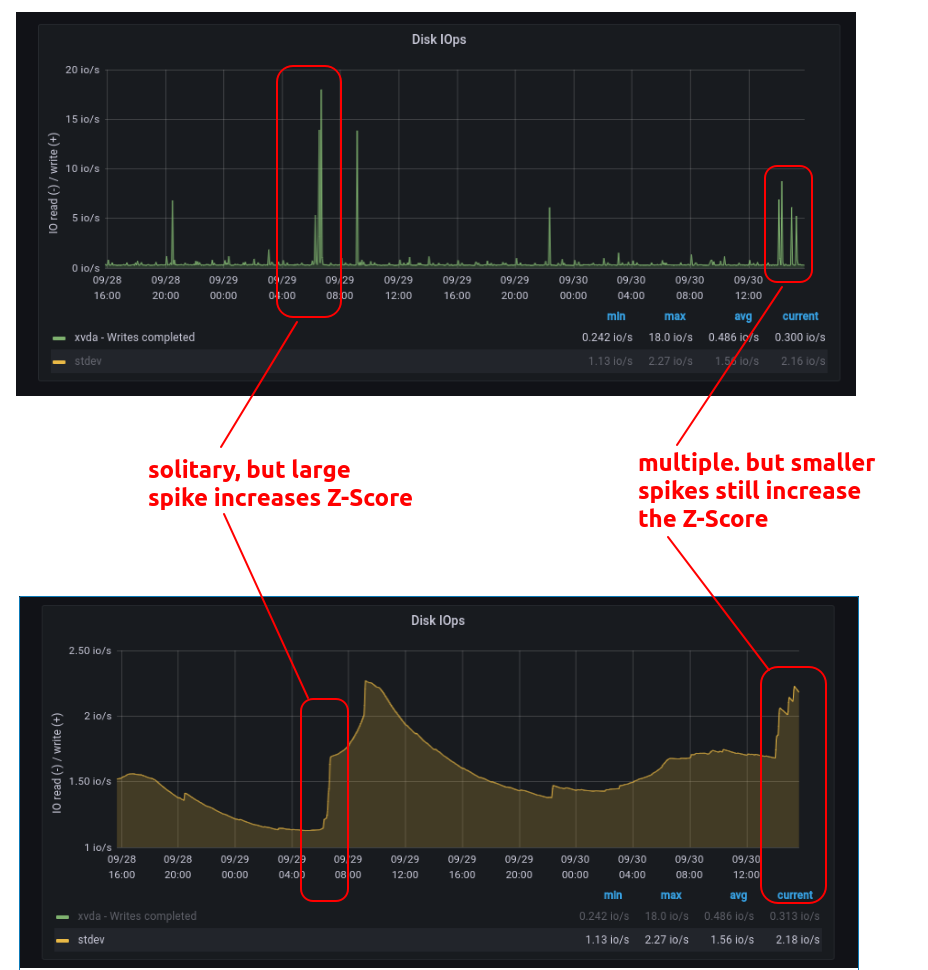
Note how the results approach a z-score of 2.5, but never exceed our threshold of 3, automatically accounting for the fact that the signal is more noisy. Another interesting point is that the anomaly query automatically handles two different scenarios as shown below:

You must be logged in to post a comment.