

The 3-sigma rule
There are many ways to detect an anomalous event in time series, ranging from simple arithmetic all the way up to leveraging neural networks like LSTMs. This post focuses on the simple “3-sigma rule”, also known as the “68-95-99” rule.
About 68% of our data would be expected to be within one standard deviation, 95% within 2, and almost all our data within 3 standard deviations of the mean.
Translating the 3 sigma rule to a flux query
The flux query we’ll be building is very close to an actual one we use at CyberSift to monitor our NiFi data pipeline queues. Some tips as you follow along:
- Follow along in the influxDB UI, in the “Explore” tab
- Set the visualization to “table”, and switch from the default “Query Builder” to “Script Editor”
On to our task. How far a datapoint is from the average in terms of standard deviation is usually called a “z-score” in data science. The formula for z-score is very simple:

A Z-score of “2” is 2 standard deviations away from the mean, and so on… Which means our first order of the day is to calculate our standard deviations and mean.
Starting off from the standard deviation; in the query below calculate the standard deviation using stddev() over the past 10 minutes via range(start: -10m). You obviously may want to increase this time window to get more accurate results.
sdev=from(bucket: "CS")
|> range(start: -10m)
|> filter(fn: (r) =>
(r["_measurement"] == "httpjson_nifi"))
|> filter(fn: (r) =>
(r["_field"] == "controllerStatus_flowFilesQueued"))
|> stddev()
|> findColumn(
fn: (key) => key._measurement == "httpjson_nifi", column: "_value"
)Note that at the end we pipe our results into a “findColumn()” function in order to extract our values as a scalar (see “troubleshooting” below). The results are stored in a variable “sdev”
Next up is calculating the mean/average, which is done in a similar manner:
avg=from(bucket: "CS")
|> range(start: -10m)
|> filter(fn: (r) =>
(r["_measurement"] == "httpjson_nifi"))
|> filter(fn: (r) =>
(r["_field"] == "controllerStatus_flowFilesQueued"))
|> mean()
|> findColumn(
fn: (key) => key._measurement == "httpjson_nifi", column: "_value"
)Once again note the use of the “findColumn()” function. Last we use the above two to calculate the ZScore of each data point:
from(bucket: "CS")
|> range(start: -10m)
|> filter(fn: (r) =>
(r["_measurement"] == "httpjson_nifi"))
|> filter(fn: (r) =>
(r["_field"] == "controllerStatus_flowFilesQueued"))
|> map(fn: (r) => ({ r with StandardDev: sdev[0] }))
|> map(fn: (r) => ({ r with Average: avg[0] }))
|> map(fn: (r) => ({ r with ZScore: (r._value-avg[0])/sdev[0] }))In the above, we use the “map()” function to insert our previously calculated mean and standard deviation. The last use of map does the actual calculation of the ZScore using the previously defined formula
This is the simplest solution I found to the requirement of adding two variables to a single table in InfluxDB, with the following results in Data Explorer:
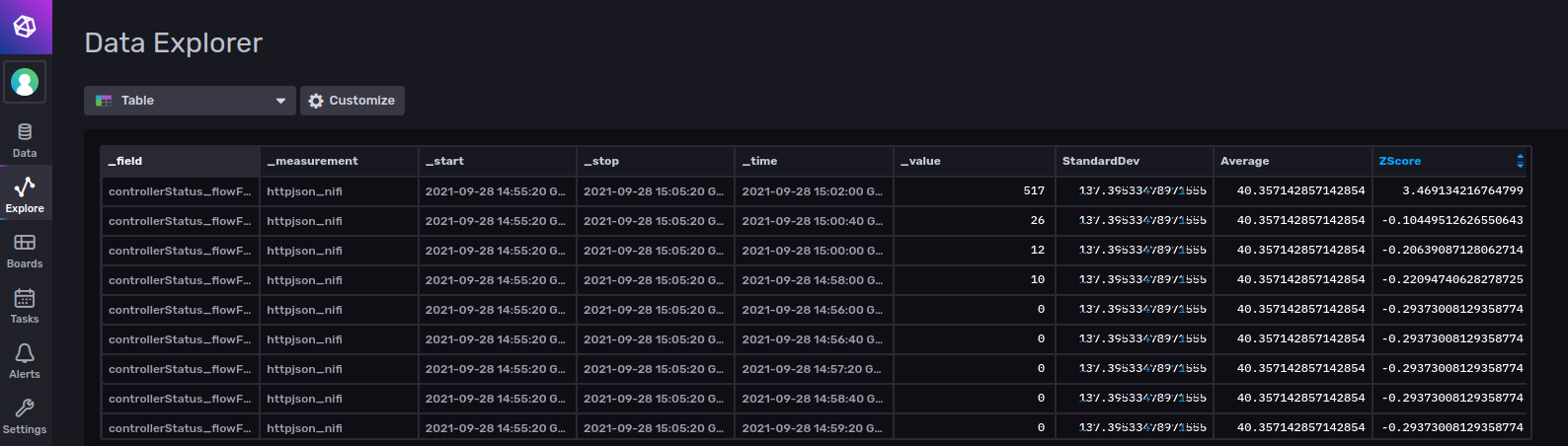
Note how we now have a “ZScore” column we can use to plot or alert on. In the above screenshot, note how the first entry has a ZScore of higher than 3… and indeed the value of “517” is much higher than we would expect and is anomalous. The below time series shows our ZScore plotted across time, and the anomaly clearly stands out:

Troubleshooting
The biggest pain while getting this to work was the fact I couldn’t use the “join()” function since it would have resulted in requiring more than two tables which join doesn’t support at the time of writing.
So next I tried to use the “sdev” and “avg” variables directly like so:
sdev=from(bucket: "CS")
[...]
|> stddev()
[...]
from(bucket: "CS")
[...]
|> map(fn: (r) => ({ r with StandardDev: sdev._value }))But this would always result in an error of:
type error ... expected {A with _value:B} but found [C]Which makes sense when you realize stddev() has a single row as output so I was trying to fit multiple values into a single one. That’s what led me to using findColumn after reading the below, which allows us to extract a single column from a table and then subsequently use the array-like notation e.g. sdev[0]
https://docs.influxdata.com/influxdb/v2.0/query-data/flux/scalar-values/
Full Flux Query
sdev=from(bucket: "CS")
|> range(start: -10m)
|> filter(fn: (r) =>
(r["_measurement"] == "httpjson_nifi"))
|> filter(fn: (r) =>
(r["_field"] == "controllerStatus_flowFilesQueued"))
|> stddev()
|> findColumn(
fn: (key) => key._measurement == "httpjson_nifi", column: "_value"
)
avg=from(bucket: "CS")
|> range(start: -10m)
|> filter(fn: (r) =>
(r["_measurement"] == "httpjson_nifi"))
|> filter(fn: (r) =>
(r["_field"] == "controllerStatus_flowFilesQueued"))
|> mean()
|> findColumn(
fn: (key) => key._measurement == "httpjson_nifi", column: "_value"
)
from(bucket: "CS")
|> range(start: -10m)
|> filter(fn: (r) =>
(r["_measurement"] == "httpjson_nifi"))
|> filter(fn: (r) =>
(r["_field"] == "controllerStatus_flowFilesQueued"))
|> map(fn: (r) => ({ r with StandardDev: sdev[0] }))
|> map(fn: (r) => ({ r with Average: avg[0] }))
|> map(fn: (r) => ({ r with ZScore: (r._value-avg[0])/sdev[0] }))

One thought on “InfluxDB Flux: Detecting anomalies in time series”
Comments are closed.