
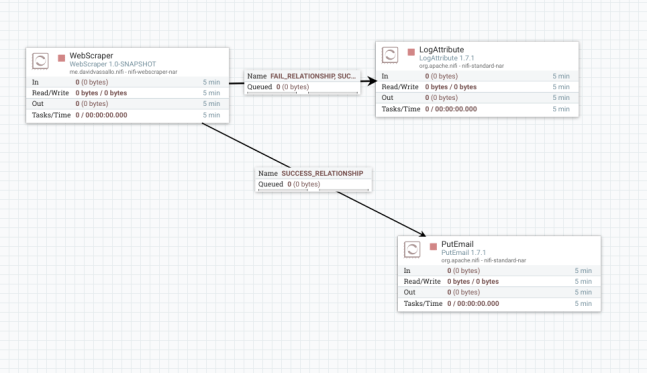
In this article we explore how to build a custom Apache Nifi processor. Our objective is to build a custom NiFi processor, written in Java, that uses Selenium to scrape an arbitrary piece of information off a web-page. The end result will look like this:
This highlights the flexibility of Apache NiFi, showing off the ability to pick off information from the Web even when a convenient REST API is not offered.
The entire processor code can be found here:
https://github.com/dvas0004/nifi-webscraper
Broadly speaking, the development process is split into four stages:
- Define properties and relationships
- Add these properties and relationships to the processor on initialization
- Code what happens when the processor is triggered
- Test
Define properties and relationships
We first need to think about what configurable properties we’d like to allow the user to change. In our case, we’re going to define three properties:
- The filepath where to find the chrome driver that selenium will use

- The URL to scrape

- The CSS selector to determine which HTML element to scrape the data off from

Next, we need to think about the outputs from our processor. In most cases, you’d have a “Success” output and a “Failed” output. These correspond to the connections between the different processors. In NiFi terms, these are relationships. In our case, we have both success and failed relationships:

Add these properties and relationships to the processor on initialization
This is standard and in fact comes along with the template from the maven archetype. In the “init” stage of the processor, we add the properties and relationships we defined above to the processor:

Code what happens when the processor is triggered
Next is the interesting part. A processor is “triggered” when it receives a new flow record, or when it is scheduled (and has no incoming relationships). In our case the code is quite simple. First, we need to create a new FlowRecord since we have no incoming relationships:

For the benefit of downstream processors, we add an attribute “webscraper.url” and insert the value of the URL_PROPERTY that we got from the user.
Next we actually fire up the selenium driver, navigate to the page, and find the element using selenium’s By.cssSelector
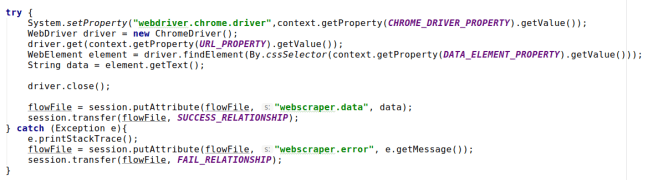
Note how if the code succeeds, we “transfer” the flowfile to the “Success” relationship, otherwise we insert the error into a new attribute and transfer the flowfile to the “Failed” relationship
From there, it’s easy to use this data in NiFi standard ways, like sending an email as shown in the video demo
Useful Links
- Official Developer Guide:
https://nifi.apache.org/docs/nifi-docs/html/developer-guide.html - Creating Custom Processors and Controllers in Apache NiFi:
https://medium.com/hashmapinc/creating-custom-processors-and-controllers-in-apache-nifi-e14148740ea - Developing a Custom Apache Nifi Processor-Unit Tests:
https://www.nifi.rocks/developing-a-custom-apache-nifi-processor-unit-tests-partI/

One thought on “Apache NiFi: Custom Web Scraper Processor – Powered by Selenium”
Comments are closed.